Заметки о Deep Learning. Влияние шума на качество функционирования свёрточных нейронных сетей. Часть 1.
Настоящей публикацией мы открываем серию заметок посвящённую тематике Deep Learning – одного из направлений машинного обучения по прецедентам. Следует сразу отметить два момента. Во-первых, из двух русскоязычных вариантов: глубинное обучение и глубокое обучение, мы оперируем вторым вариантом, так как считаем, что именно вариант «глубокое обучение» более корректный (детальное рассмотрение терминологической проблематики выходит за рамки данной статьи и возможно будет подробнее изложено в одной из следующих публикаций). Во-вторых, мотивацией к написанию данных заметок являются вопросы из серии: «Почему работает глубокое обучение?», «Почему нейронные сети такие эффективные?», «Каковы границы области адекватного применения современных глубоких архитектур?» и т.п. При этом в публикациях мы не затрагиваем следующих моментов: сильный интеллект и человеческая цивилизация; азы функционирования алгоритмов машинного обучения; настройка библиотек и фреймворков и т.п. Таким образом, данная серия заметок должна быть интересна читателям (как мы надеемся) с одной стороны уже разбирающихся в основах, но при этом задающих себе всяческие каверзные вопросы.
Итак рассмотрим первую задачу. Введём в рассмотрение чёрно-белые изображения, содержащие десять классов объектов, которые необходимо распознать:

Каждое изображение имеет размер 24x24 пикселя, активный пиксель кодируется 1 (на рисунке выше – это чёрный цвет). Для опознавания наборов данных этого формата, присвоим данным объектам код R39_10.
Обучим на этих изображениях свёрточную сеть следующего формата (присвоим ей идентификатор 39_10_cnn_1):
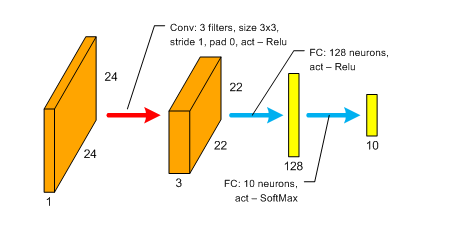
Отметим, что для обучения сети использовались исходные эталонные изображения объектов, без каких либо их модификаций (зашумление, сдвиг, масштабирование, вращение и т.п). Следовательно, мы скорее учили сеть запоминать объекты и различия между ними, нежели порождать какие-то обобщения, связанные с возможными модификациями эталонов. Обучение сети проводилось в течении 20-ти эпох методом Adadelta, размер минибатча 128 объектов. Минимизировалась функция перекрёстной энтропии. Использовался фреймворк Keras 0.3.3. Длительность одной эпохи обучения на GPU NVIDIA Geforce Titan X – 15 секунд.
Финальные интегральные показатели качества функционирования сети на тестовом множестве: Test score – 1.19209317972e-07, Test accuracy – 1.0.
А теперь наложим на тестовые эталонные изображения импульсный шум, который будет «выбивать» пиксели, изменяя их значения на противоположное. Пространственное распределение шумовых отсчётов – равномерное. Естественно, что с увеличением уровня шума (числа «выбитых» пикселей) качество классификации объектов сетью будет деградировать. Количественные характеристики деградации приведены на рисунке (использовалась тестовая выборка объёмом 100 000 объектов на каждый уровень шума):
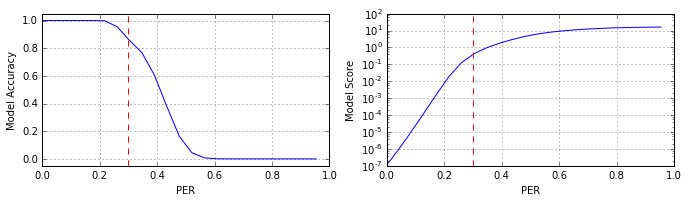
Отметим, что для измерения уровня шума мы используем понятие PER (Pixel Error Rate), по аналогии с BER (Bit Error Rate). Как видно из рисунка при достижении уровня шума ≈0.3 PER (175 «выбитых» пикселей) показатель accuracy снижается до ≈0.857. Чтобы визуально оценить степень искажения изображений, на рисунках ниже приведены некоторые из образцов сигналов при различной интенсивности шума.
Уровень шума ≈0.069 PER (40 «выбитых» пикселей):

Уровень шума ≈0.174 PER (100 «выбитых» пикселей):

Уровень шума ≈0.3 PER (175 «выбитых» пикселей):

Уровень шума ≈0.52 PER (300 «выбитых» пикселей):

Как видно из рисунка выше, при уровне шума ≈0.3 PER (175 «выбитых» пикселей) уровень искажений таков, что визуально определить принадлежность образца тому или иному классу достаточно затруднительно (особенно если убрать подсказки и перемешать изображения). Тем не менее, нейросеть состоящая всего из двух скрытых слоёв (одного свёрточного и одного полносвязного) при данном уровне шума в среднем делает всего ≈14.33% ошибок. И это вполне приличный результат.
Почему при ≈14.33% ошибок мы пишем о «приличном результате»? Дело в том что как уже указывалось выше, сеть училась на чистых образцах, в режиме скорее запоминания, нежели обобщения и ей ничего не было известно о статистических характеристиках шума и о модели искажения сигнала. Поэтому способность классификатора фильтровать шум и сохранять работоспособность выглядит достаточно удивительно. А для людей «не в теме» вообще выглядит как магия.
Конечно знающий читатель скажет, что здесь нет ничего удивительного, что обобщённую аппроксимационную теорему никто не отменял. И это действительно так, нейронная сеть как аппроксиматор «давит» шум, выделяя тренд. Но одно дело знать это в теории, и совсем другое – увидеть это воочию. Для людей начинающих свой путь в Deep Learning подобное упражнение весьма полезно.
У пытливого читателя, после короткого осмысления приведённых результатов (не даром говорится: «аппетит приходит во время еды»), как правило, сразу же возникает пять основных вопросов: «Какова структура ошибок?», «Как падает уверенность классификатора с ростом интенсивности шума?», «Какова структура весов модели?», «Как влияет архитектура сети на устойчивость классификации?», «Можно ли улучшить полученный результат?».
Вопросы конечно правильные и интересные.
Продолжение: Часть 2.
05 мая 2016 года.
Андрей Макаренко,
группа «Конструктивная Кибернетика».
Обсуждение: contact@rdcn.ru
Ключевые слова: Глубокое машинное обучение, свёрточные сети, шумы, качество классификации.
