Заметки о Deep Learning. Влияние шума на качество функционирования свёрточных нейронных сетей. Часть 2.
Итак, продолжаем исследовать вопросы обозначенные в прошлой заметке. Как было установлено, при обучении нейронной сети на чистых эталонах, при достижении уровня шума ≈0.3 PER (175 «выбитых» пикселей) показатель accuracy снижается до ≈0.857, и далее нейронная сеть очень быстро деградирует до полной неработоспособности. Естественно, возникает задача улучшения качества функционирования классификатора на зашумлённых данных.
Один из возможных подходов к решению поставленной задачи в общем-то лежит на поверхности – это обучение сети на зашумлённых данных. С этой целью мы провели два эксперимента.
Первый эксперимент. На исходные эталонные изображения объектов накладывался шум согласно принятой в эксперименте модели (см. предыдущую заметку). Уровень шума (число «выбитых» пикселей) при обучении одной конкретной модели – фиксировался. Но всего было обучено 23 модели, при разных уровнях шума (от 5-ти до 550-ти «выбитых» пикселей). Тестовые выборки модифицировались также. Параметры оптимизатора не изменялись, за исключением длительности обучения – оно было увеличено до 40 эпох.
Далее следовал этап валидации предобученных свёрточных нейросетей. Для этого применялась та же самая выборка, что и в прошлом эксперименте. Результаты валидации для нескольких моделей приведены на рисунке (синий 0 PER, красный ≈0.347 PER, оранжевый ≈0.651 PER, красный ≈0.347 PER, циан ≈0.955 PER):
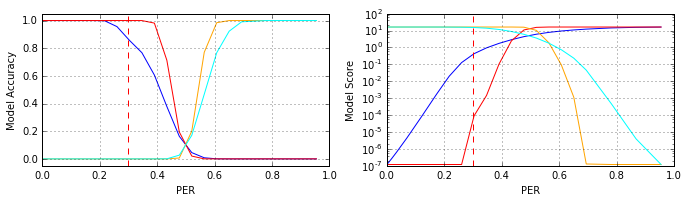
Как видно из рисунка (см. красный график, модель #11), обучение нейросети на зашумлённых данных способно существенно улучшить её обобщающую способность: показатель accuracy снижается до 0.952 при достижении шумом уровня 0.4 PER, в то время как базовая модель (обученная на чистых эталонных данных) при этом же уровне шума деградирует практически до уровня «подбрось монетку».
Тем не менее, модели, обученные при более высоком уровне шума (оранжевый и циан цвета графиков, соответственно #18 и #22 модели), на первый взгляд, демонстрируют контринтуитивное поведение: сильно ошибаются на слабозашумлённых данных и прекрасно отрабатывают при сильных шумах. В чём причина подобного поведения? Ответ, который обычно приходит на ум новичкам в области машинного обучения и статистического обнаружения сигналов: «модель учили при сильном уровне шума, она ничего не знает о структуре чистого сигнала, поэтому и ошибается» – в корне неверный. Правильный ответ другой.
Для начала подсказка. Вспомним применяемую нами модель смешивания сигнала и шума (см. предыдущую заметку): на тестовые эталонные изображения накладывается импульсный шум, который «выбивает» пиксели, изменяя их значения на противоположное. Пространственное распределение шумовых отсчётов – равномерное. Догадались?
В предыдущей заметке были приведены некоторые из образцов сигналов при различной интенсивности шума до уровня ≈0.52 PER включительно. А ниже мы продемонстрируем образцы сигналов при более высокой интенсивности шума. Отметим, что активный пиксель в изображениях кодируется 1 (на рисунках ниже – это чёрный цвет).
Уровень шума ≈0.781 PER (450 «выбитых» пикселей):

Уровень шума ≈0.955 PER (550 «выбитых» пикселей):

Таким образом, в силу принятой модели смешивания сигнала и шума, высокая интенсивность шума – инвертирует сигнал (формирует негативное отображение), практически не нарушая его геометрическую структуру (в этом сильный шум подобен слабому). В тоже время шум средней интенсивности – практически разрушает геометрическую структуру эталонных сигналов (см. соответствующие рисунки в предыдущей заметке). Эта особенность и порождает такое странное, на первый взгляд, поведение классификаторов. Исходя из изложенного стоит также отметить момент (акцент особенно полезный для новичков): при моделировании процессов и систем и/или анализе реальных данных, следует очень внимательно подходить к выбору модели смешивания сигнала и шума, проверять её на адекватность, и не пренебрегать исследованием эффектов (артефактов), которые может порождать та или иная модель.
Итак, получается, что если каким-то образом объединить решения классификаторов #11 и #18, то возможно существенно расширить зону адекватной классификации. Отметим, что техника параллельного объединения классификаторов называется «ансамбль сетей» (ensembles models, см. для примера презентацию). Но решение с объединением выглядит как-то громоздко. Возможно ли обойтись одной моделью? Да, возможно, и это демонстрирует:
Второй эксперимент. На исходные эталонные изображения объектов также накладывался шум, согласно принятой в эксперименте модели. Но, в отличии от первого эксперимента, уровень шума (число «выбитых» пикселей) при обучении модели – равномерно варьировался от 1-го до 550-ти «выбитых» пикселей). Тестовая выборка модифицировалась также. Отметим, что подобная техника подготовки данных (зашумление обучающей и тестовой выборок) называется «шумовая аугментация данных» (data augmentation / noise addition, см. для примера: статья 1, статья 2). Получившийся в итоге результат приведён на рисунке:
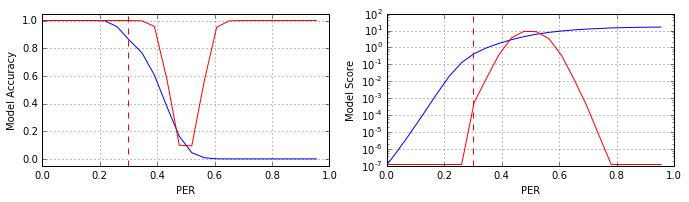
Как видно из рисунка (см. красный график), полученная нейросеть (#V1) фактически эквивалентна ансамблю классификаторов #11 и #18. То есть нейросеть обобщила входные сигналы с учётом возможности формирования их негативных отображений.
После анализа полученных результатов, вновь возникает закономерный вопрос: возможно ли нейтрализовать деградацию функциональности классификатора в области 0.4–0.6 PER? Мотивация этого вопроса существенно возрастает после изучения характеристик моделей #13 – #16, полученных в рамках первого эксперимента. Базовые характеристики моделей приведены на рисунке (#13 – зелёный, #14 – синий, #15 – оранжевый и #16 – розовый графики, соответственно):
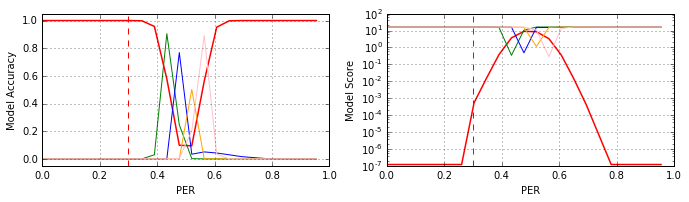
Понятно, что данные модели (#13 – #16), даже при их объединении с моделью #V1, полученной в рамках второго эксперимента, не имеют практической ценности, но сам факт: что глубокие нейросетевые классификаторы тем не менее пытаются настраиваться на подавление шума, существенно разрушающего геометрическую структуру эталонных сигналов – наводит на определённые мысли.
Продолжение: Часть 3.
07 мая 2016 года.
Андрей Макаренко,
группа «Конструктивная Кибернетика».
Обсуждение: contact@rdcn.ru
Ключевые слова: Глубокое машинное обучение, свёрточные сети, шумы, качество классификации.
