Заметки о Deep Learning. Влияние шума на качество функционирования свёрточных нейронных сетей. Часть 3.
Итак, пытаемся улучшить классификатор #V1, который был получен в рамках экспериментов, изложенных в прошлой заметке. Исходная постановка задачи и мотивация приведены в 1-й части серии.
При работе со свёрточными сетями часто применяется известный подход: из изображения подаваемого на вход сети обязательно следует вычитать кадр, формируемый как среднее по выборке данных. Давайте посмотрим, как это правило повлияет на качество классификации в нашем случае.
Кадр, полученный усреднением выборок применяемых для обучения и тестирования свёрточной нейронной сети #V1, приведён на рисунке:
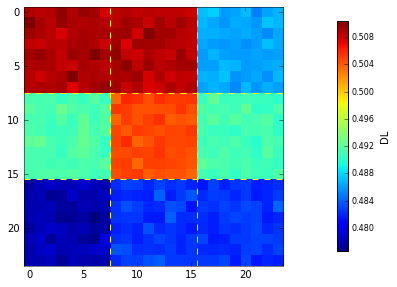
Как видно из рисунка, средний кадр имеет весьма выраженный и достаточно замысловатый пространственный паттерн. Его изучение, в привязке к геометрии изображений исходных классов (см. 1-ю часть серии), достаточно увлекательное упражнение, полезное для понимания сути самого подхода – центрирования выборок, тем более что этот подход вполне себе имеет теоретическое обоснование.
Итак, после центрирования выборок, была обучена модель #V2, структура которой и режим обучения полностью соответствовали таковым для сети #V1 (см. заметки: 1 и 2). Результаты обучения приведены на рисунке (красный – модель #V1, синий – модель #V2):
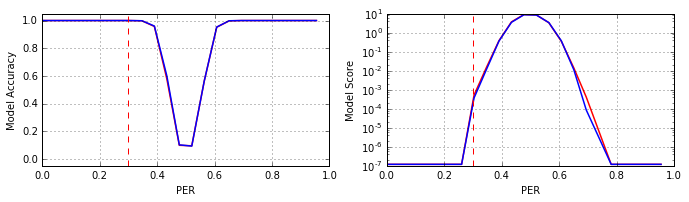
Как видно из рисунка попиксельное центрирование входных данных не изменило параметр Accuracy, но положительно повлияло на «уверенность» модели #V2 при уровнях шумов в районе 0.7 PER.
Таким образом, в нашем случае принцип «вычти средний кадр» конечно сработал, но далеко не так как ожидалось (напомним, что после синтеза модели #V1 мы ведём борьбу за качество классификатора в области 0.4–0.6 PER). Тем не менее, следует отметить: данный принцип – не догма, и тем более не прямое требование теоремы, потому не стоит его применять по умолчанию в своих задачах, его эффективность необходимо всегда тестировать. И что самое интересное, подобный совет справедлив для большинства «фишек» имеющих отношение к нейронным сетям в частности, и глубокому обучению в общем.
В рамках решаемой задачи возникает ещё один закономерный вопрос: а насколько полученные характеристики качества классификатора (см. графики на предыдущем рисунке), специфичны именно для свёрточной сети (см. архитектуру сети 39_10_cnn_1, в первой заметке)? С целью ответа на данный вопрос была протестирована исключительно полносвязная сеть следующего формата (присвоим ей идентификатор 39_10_mlp_1):
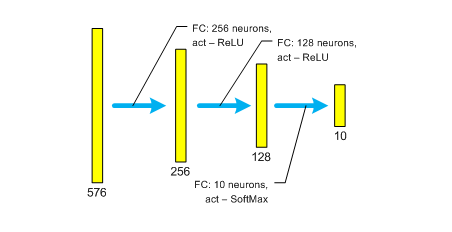
Из сравнения архитектур 39_10_cnn_1 и 39_10_mlp_1 видно, что они различаются только параметрами первого скрытого слоя, причём его размер у полносвязной сети – 256 нейронов. Почему именно 256? Это сделано намеренно, чтобы сложности двух сетей были сопоставимы. Имеется в виду количество параметров (веса и смещения), которые оптимизируются в ходе обучения. Так вот, у сети 39_10_cnn_1 – 187 304, а у сети 39_10_mlp_1 – 181 898 параметров. Здесь следует отметить, что в Deep Learning, помимо прочих, есть одно негласное правило: «если хочешь понять что произошло, всегда меняй только один параметр». Естественно, у этого правила, как и у любого другого, есть исключения.
Так вот, в рамках нашей задачи, между сетями 39_10_cnn_1 и 39_10_mlp_1 никакой заметной (статистически значимой) разницы обнаружено не было. Более того, они количественно схожим образом (см. рисунок выше) ведут себя даже в ситуациях включения/отключения попиксельного центрирования входных данных. Из этого конечно ни в коем случае нельзя делать вывод об эквивалентности полносвязных и свёрточных сетей, а получившийся результат возможно корректно распространять только на данную задачу, и более того, только на случай замены первого скрытого слоя. Ибо, как будет показано в одной из следующих серий цикла «Заметки о Deep Learning», есть задачи со схожей постановкой, но в них между полносвязными и свёрточными сетями обнаруживается колоссальная разница.
В общем, промежуточный итог таков. Мы получили улучшенную модель #V2, проверили также полносвязную архитектуру, но главную задачу: обеспечить качество классификатора в области 0.4–0.6 PER – не решили. Значит необходимо «копать» дальше.
Продолжение: Часть 4.
12 мая 2016 года.
Андрей Макаренко,
группа «Конструктивная Кибернетика».
Обсуждение: contact@rdcn.ru
Ключевые слова: Глубокое машинное обучение, свёрточные сети, шумы, качество классификации.
