Заметки о Deep Learning. Влияние шума на качество функционирования свёрточных нейронных сетей. Часть 4.
Продолжаем бороться за качество классификатора в области 0.4–0.6 PER. Отправной точкой для нас является сеть #V2, полученная в прошлой заметке. Начало эпопеи изложено в 1-й части данной серии.
В попытке улучшить сеть #V2 был применён ещё один известный подход: изменить соотношение обучающих и тестовых примеров так, чтобы объекты, ошибочно распознанные на равномерной выборке, в модифицированной выборке встречались чаще. Для этого были сформированы обучающее и тестовое множества, в которых классы имеют равномерное распределение, но при этом 30% множества имеют искажения шумом равномерно распределённым в интервале 0.0–1.0 PER, а 70% множества зашумлены на уровне 0.4–0.48 PER. Результаты полученной модели (#V3) приведены на рисунке (#V2 – красный, #V3 – синий):
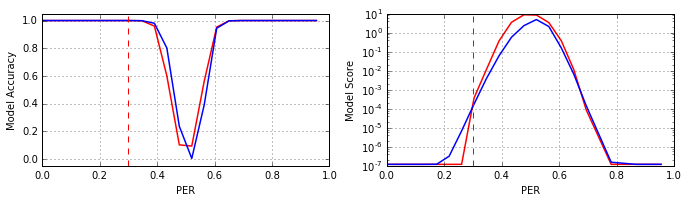
Как видно из рисунка, модель #V3 улучшила качество классификации в зоне 0.4–0.5 PER, но потеряла его в области 0.5–0.6 PER. Если при обучении 70% объектов исказить на уровне 0.4–0.6 PER, то новая модель не демонстрирует каких либо значимых отличий от модели #V2. Если нейросеть учить на выборке, в которой 70% объектов зашумлены на уровне 0.52–0.6 PER, то результаты получаются почти «зеркальными» относительно модели #V3, см. рисунок (#V3' – зелёный):
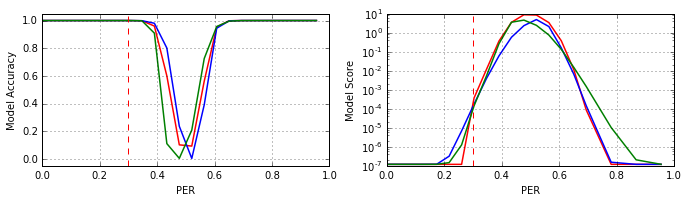
Таким образом, в принципе возможно сформировать ансамбль из модели #V3 и её «зеркального» антипода #V3', и сузить воронку ошибок в зоне 0.4–0.6 PER, но избавиться от воронки ошибок этот манёвр не позволит. Следовательно, для решения задачи требуется что-то другое.
К нейросети #V2 была применена техника dropout (для объяснения см. статью и ссылки в ней) на первом полносвязном слое (с уровнем «выключения» нейронов 0.5). Результаты модели #V2' (синий) в сравнении с моделью #V2 (красный) приведены на рисунке:
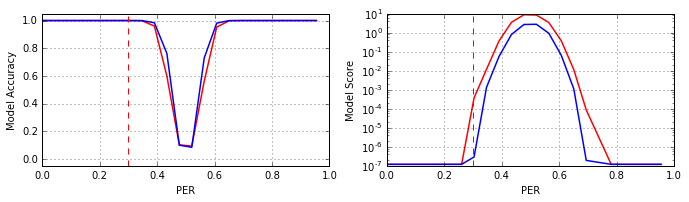
Из рисунка видно, что техника dropout оказалась весьма эффективной, модель #V2' лишь слегка уступает ансамблю сетей #V2 и #V3' по параметру Accuracy и существенно превосходит их по уверенности ответов (параметр Score). При том, что по сложности сеть #V2' это та же самая сеть #V2, и время её обучения лишь незначительно превосходит таковое сети #V2, тогда как ансамбль сетей #V2 и #V3' требует обучения по крайней мере двух моделей.
В качестве «чего-то иного» был также опробован экстенсивный путь расширения сети: добавление слоёв, изменение параметров слоёв (количество нейронов, формат свёрточных ядер и схемы их связывания), добавление новых типов слоёв (в частности MaxPooling), но обойти сеть #V2' этим путём также не удалось.
В общем требуется осмысление ситуации.
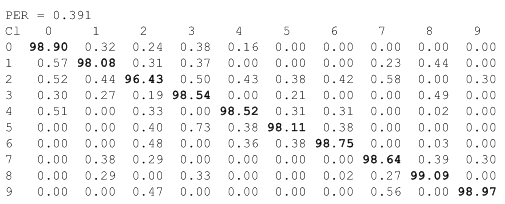
Поэтому прежде чем продолжить эксперименты по ликвидации воронки ошибок, давайте посмотрим на структуру ошибок нашей предобученной свёрточной сети #V2' в зоне экстремальных уровней шума (вблизи точки 0.5 PER). Для этого изучим матрицы ошибок (Confusion Matrix).
Уровень шума ≈0.391 PER (225 «выбитых» пикселей):
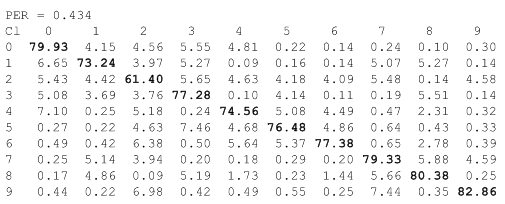
Уровень шума ≈0.434 PER (250 «выбитых» пикселей):
Уровень шума ≈0.477 PER (275 «выбитых» пикселей):
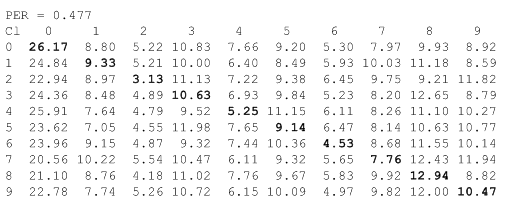
Как видно из таблиц (Confusion Matrix), при переходе от уровня шума ≈0.434 PER к уровню ≈0.477 PER, качество классификатора #V2' существенно деградирует, до уровня «подбрось монетку». Структуру деградации весьма информативно раскрывает анализ падения уровня уверенности классификатора в ответах. Гистограммы распределения оценок параметра Confidence для 5-го класса объектов приведены на рисунке:
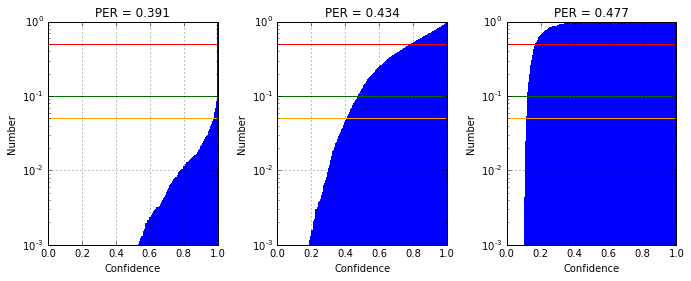
На вышеприведённых гистограммах горизонтальные уровни отмечают объём тестовой выборки, лежащий справа от данного уровня уверенности: красный – 50%, зелёный – 90%, оранжевый – 95%. Из совместного анализа Confusion Matrix и Confidence Histogram, возможно сделать много сильных и полезных выводов. Для новичков следует отметить момент, что анализ Confidence Histogram конечно громоздок, особенно при большом количестве классов, но зато весьма информативен, особенно в части анализа устойчивости классификатора к ошибкам во входных данных, при возрастании уровня шумов.
Детальный совместный анализ Confusion Matrix и Confidence Histogram Cl 5, оставляем в качестве самостоятельной работы для заинтересовавшихся читателей. А тем временем дадим ответ на ещё один вопрос, поставленный в 1-й части данной серии: «Какова структура весов модели?».
На рисунке ниже приведена визуализация весов 2D свёрточных ядер первого скрытого слоя нашей предобученной сети #V2':
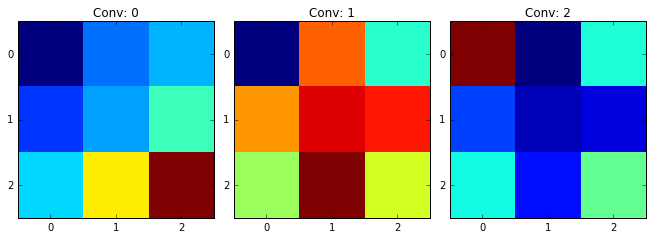
Просмотрев вышеприведённый рисунок, опытный специалист конечно уловит назначение ядер Conv 1 и Conv 2 и их антисимметрию, а также весьма специфический характер ядра Conv 0 (оно Вам ничего не напоминает?). Кстати, отметим, для тех кто не совсем в теме, эти фильтрующие паттерны сеть «придумала» сама в процессе обучения, ибо инициализировалась она равномерно распределённым шумом малой интенсивности. Вообще вопрос начальной инициализации сети – один из ключевых для успешного обучения сети. И мы постараемся это продемонстрировать в одной из следующих серий цикла «Заметки о Deep Learning».
Конечно, для новичков анализировать и пытаться понять структуру обучившейся сети по внешнему виду ядер – то ещё упражнение, поэтому обычно делают ещё и визуализацию рецептивных полей. Не будем выбиваться из мейнстрима и мы. На рисунке ниже приведены входные данные (первая строка) и выходы трёх свёрточных ядер нашей глубокой сети (архитектура модели приведена в 1-й части данной серии):
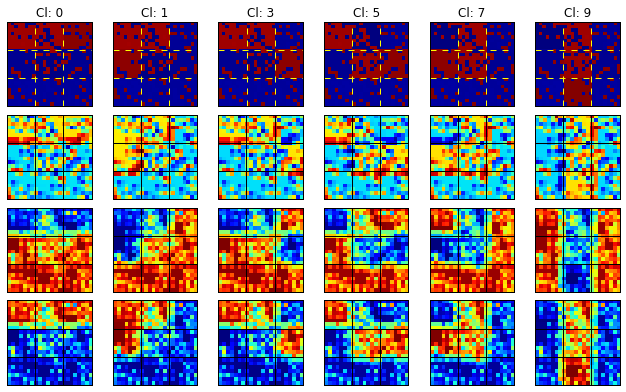
Ну а теперь суть фильтрующих паттернов сети Вам стала понятна? Отметим, что визуализация приведена для уровня шума ≈0.174 PER, это компромиссное значение: с одной стороны шум уже активно «разъедает» изображение, а с другой – человек ещё в силах визуально восстановить картину.
На самом деле с интерпретацией Conv 1 и Conv 2 никаких проблем не должно быть: Conv 2 – фильтрует импульсный шум для «позитивного» изображения (когда уровень шума ниже 0.5 PER); Conv 1 – делает тоже самое для «негативного» изображения (когда уровень шума выше 0.5 PER). А вот что делает Conv 0? Этот вопрос оставляем в качестве самостоятельной работы для заинтересовавшихся читателей. На самом деле ответ очень интересный и достаточно неожиданный. Дерзайте!
Проведённый экспресс-анализ структуры сети #V2' и полученные результаты в принципе позволяют продолжить эксперименты по ликвидации воронки ошибок, но экстенсивно (за счёт «грубой силы») этот вопрос решить не получится (почему?), требуется некое экспансивное решение. Но прежде чем его сформировать, далее мы рассмотрим в рамках цикла «Заметки о Deep Learning» ряд тем и вопросов, которые на первый взгляд не имеют никакого отношения к данной задаче.
Продолжение следует.
23 мая 2016 года.
Андрей Макаренко,
группа «Конструктивная Кибернетика».
Обсуждение: contact@rdcn.ru
Ключевые слова: Глубокое машинное обучение, свёрточные сети, шумы, качество классификации.
